
 Le 18 novembre 2025 marque un tournant dans l'histoire de l'intelligence artificielle. Google a lancé Gemini 3, son modèle d'IA le plus avancé à ce jour, et les chiffres parlent d'eux-mêmes : avec un score de 1501 Elo sur le classement LMSys Arena, Gemini 3 Pro domine désormais tous les modèles d'IA publiquement disponibles, dépassant GPT-5.1 d'OpenAI et Claude 4.5 Sonnet d'Anthropic. Pour la première fois depuis le lancement de ChatGPT en novembre 2022, Google reprend la tête de la course à l'IA générative avec un modèle qui combine raisonnement de niveau doctoral, compréhension multimodale native et capacités agentiques révolutionnaires.
Le 18 novembre 2025 marque un tournant dans l'histoire de l'intelligence artificielle. Google a lancé Gemini 3, son modèle d'IA le plus avancé à ce jour, et les chiffres parlent d'eux-mêmes : avec un score de 1501 Elo sur le classement LMSys Arena, Gemini 3 Pro domine désormais tous les modèles d'IA publiquement disponibles, dépassant GPT-5.1 d'OpenAI et Claude 4.5 Sonnet d'Anthropic. Pour la première fois depuis le lancement de ChatGPT en novembre 2022, Google reprend la tête de la course à l'IA générative avec un modèle qui combine raisonnement de niveau doctoral, compréhension multimodale native et capacités agentiques révolutionnaires.
Ce qui distingue véritablement Gemini 3, c'est son déploiement stratégique sans précédent : dès le jour du lancement, le modèle était simultanément intégré dans la recherche Google (2 milliards d'utilisateurs mensuels via AI Overviews), l'application Gemini (650 millions d'utilisateurs), et les outils développeurs via AI Studio et la nouvelle plateforme Google Antigravity. Cette stratégie de distribution instantanée à l'échelle planétaire confère à Google un avantage compétitif majeur que ses concurrents auront du mal à égaler. Avec des infrastructures TPU propriétaires permettant de réduire les coûts d'entraînement de 80% par rapport aux GPU NVIDIA, et un écosystème de 13 millions de développeurs déjà en place, Google démontre qu'il ne joue plus seulement la course aux performances brutes, mais transforme l'IA en une infrastructure omniprésente intégrée dans les outils quotidiens de milliards d'utilisateurs.
Passer à Google Workspace Business
• Code promo Business Starter: GA369TYLJNAFMTU (-10%)
• Code promo Business Standard: 66Q9AE7VPGH66WF (-10%)
L'Architecture Révolutionnaire de Gemini 3
Une Multimodalité Native Repensée
L'une des innovations fondamentales de Gemini 3 réside dans son architecture multimodale native, qui traite simultanément le texte, les images, l'audio, la vidéo et le code au sein d'un même pipeline de traitement. Contrairement aux modèles concurrents comme GPT-4 qui ont ajouté des capacités visuelles par extension, Gemini 3 a été conçu dès le départ pour comprendre et raisonner sur plusieurs modalités de manière unifiée. Cette approche repose sur des encodeurs spécialisés qui convertissent chaque type de données en une séquence de tokens partageant un espace commun, permettant ainsi une attention croisée entre les différentes modalités.
Chapter 3 Multimodal architectures | Multimodal Deep Learning
L'architecture utilise probablement une approche Mixture-of-Experts (MoE) avec des couches de transformers décoder-style. Ce design permet d'augmenter massivement la capacité du modèle tout en maintenant une latence acceptable grâce à l'activation sélective d'experts spécialisés. Les tokens issus de différentes sources (pixels d'images transformés via un encodeur de type Vision Transformer, formes d'ondes audio tokenisées, frames vidéo échantillonnées) sont traités conjointement, permettant au modèle de faire des références croisées entre un diagramme visuel, une explication textuelle et un fragment de code.
Cette multimodalité se traduit par des performances spectaculaires : Gemini 3 Pro atteint 81% sur MMMU-Pro et 87,6% sur Video-MMMU, établissant de nouveaux standards dans la compréhension multimodale. Sur Video-MMMU, Gemini 3 devance GPT-5.1 de 5 à 7 points de pourcentage, démontrant une capacité exceptionnelle à analyser des informations temporelles et spatiales complexes. Cette supériorité permet des applications pratiques révolutionnaires, de l'analyse de vidéos médicales pour détecter des anomalies à l'évaluation de performances sportives en temps réel.
Le Raisonnement de Niveau Doctoral
Le cœur de Gemini 3 réside dans ses capacités de raisonnement à la pointe de l'état de l'art. Sur le benchmark Humanity's Last Exam, considéré comme l'un des tests les plus difficiles jamais conçus pour l'IA, Gemini 3 Pro atteint 37,5% en mode standard, soit une amélioration de près de 11 points de pourcentage par rapport à GPT-5.1 (26,5%). Ce benchmark teste les connaissances et le raisonnement à la limite de la compréhension humaine, avec des questions extrêmement complexes nécessitant une expertise approfondie dans de multiples domaines.
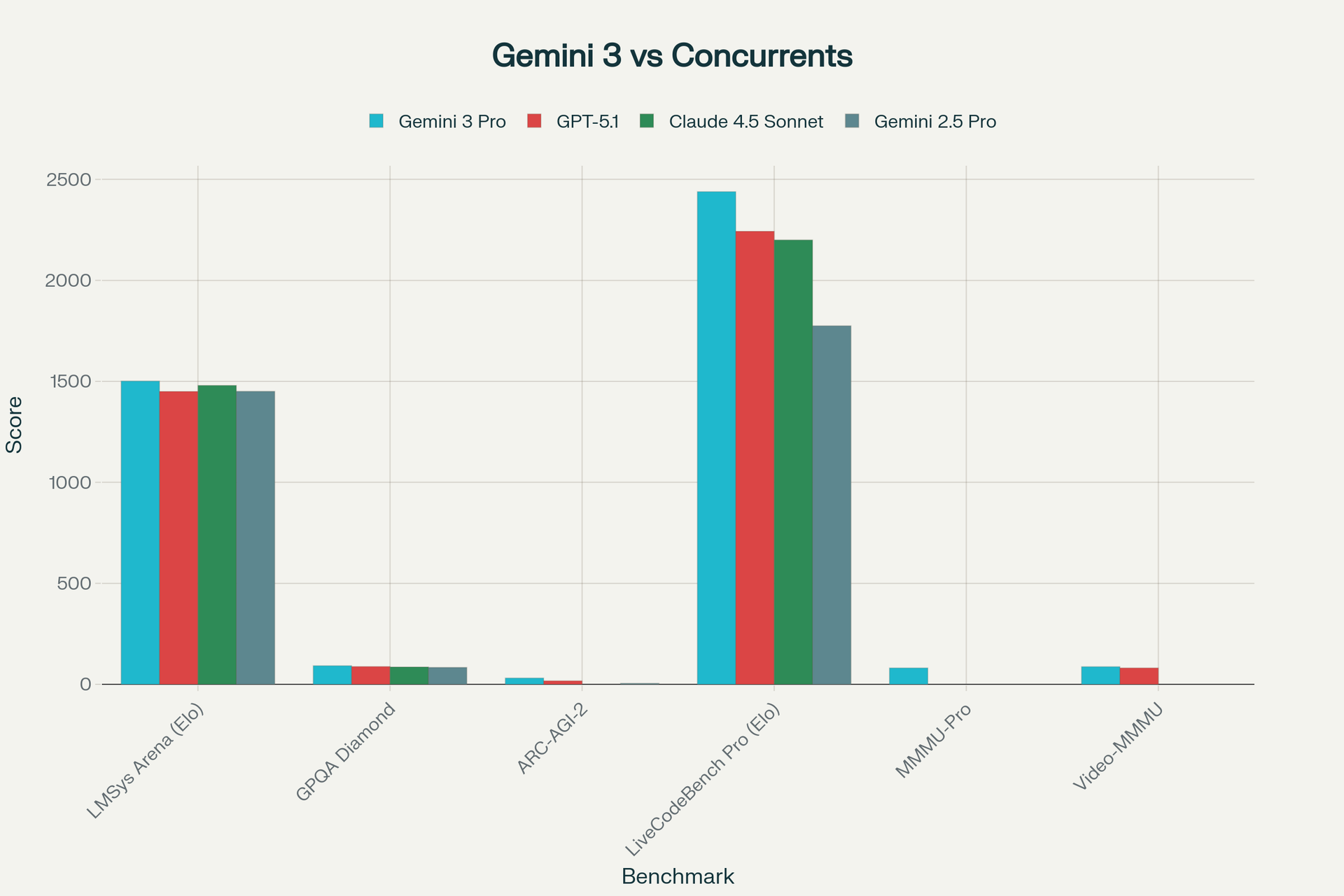
Comparaison des performances de Gemini 3 Pro face à GPT-5.1, Claude 4.5 Sonnet et Gemini 2.5 Pro sur les benchmarks clés de l'industrie
Encore plus impressionnant, le mode Gemini 3 Deep Think pousse ce score à 41%, un niveau jamais atteint auparavant par aucun modèle d'IA. Deep Think utilise le raisonnement parallèle et l'apprentissage par renforcement pour allouer un temps de calcul supplémentaire aux problèmes les plus complexes, imitant le processus cognitif humain où les défis difficiles nécessitent une réflexion prolongée. Sur le benchmark GPQA Diamond, qui teste le raisonnement scientifique de niveau doctoral, Gemini 3 atteint 91,9% (et 93,8% avec Deep Think), surpassant GPT-5.1 de près de 4 points.
Le domaine du raisonnement abstrait révèle peut-être l'avancée la plus spectaculaire. Sur ARC-AGI-2, qui évalue la capacité à résoudre des problèmes totalement nouveaux sans s'appuyer sur des patterns appris, Gemini 3 Pro obtient 31,1%, soit presque le double de GPT-5.1 (17,6%) et plus de six fois le score de son prédécesseur Gemini 2.5 Pro (4,9%). Avec Deep Think, ce score bondit à un 45,1% sans précédent, démontrant une capacité réelle à généraliser et à inventer de nouvelles stratégies de résolution. Cette performance suggère que Gemini 3 ne se contente pas de réciter des informations mémorisées, mais possède une véritable capacité de raisonnement abstrait.
Excellence Mathématique et Algorithmique
Dans le domaine mathématique, Gemini 3 établit de nouveaux records qui illustrent la profondeur de son raisonnement. Sur le AIME 2025 (American Invitational Mathematics Examination), un test de mathématiques de niveau olympique, Gemini 3 atteint 95% de réussite sans utiliser d'outils externes, contre environ 71% pour GPT-5. Cette différence de 24 points de pourcentage révèle une intuition mathématique intrinsèque bien supérieure, permettant au modèle de résoudre des problèmes complexes sans dépendre d'exécution de code. Avec l'exécution de code activée, Gemini 3 et GPT-5.1 atteignent tous deux le score parfait de 100%, mais la performance de base de Gemini démontre une compréhension fondamentale plus robuste.
Sur MathArena Apex, considéré comme l'un des benchmarks mathématiques les plus difficiles au monde, Gemini 3 Pro établit un nouveau record avec 23,4%, une performance plus de 20 fois supérieure à celle des modèles précédents. Ce benchmark teste la résolution de problèmes mathématiques avancés de type olympique, et le fait que Gemini 3 soit actuellement le seul modèle à montrer des capacités significatives sur ce test témoigne de sa supériorité en raisonnement mathématique.
Domination en Génération de Code
Pour les développeurs, Gemini 3 représente un bond en avant majeur. Sur SWE-Bench Verified, qui mesure la capacité des agents de codage à corriger des bugs réels dans des bases de code open source, Gemini 3 atteint 76,2%, une amélioration spectaculaire par rapport aux 59,6% de Gemini 2.5 Pro. Bien que Claude 4.5 Sonnet conserve une légère avance à 77,2% sur ce benchmark spécifique de débogage, Gemini 3 domine dans le développement algorithmique créatif.
Sur LiveCodeBench Pro, qui évalue la génération d'algorithmes complexes à partir de zéro, Gemini 3 Pro obtient un score Elo impressionnant de 2439, soit près de 200 points de plus que GPT-5.1 (2243). Cette supériorité dans la résolution de problèmes algorithmiques complexes fait de Gemini 3 le choix privilégié pour la programmation compétitive, le développement d'algorithmes innovants et la génération de code nécessitant une réflexion créative profonde.
Google déploie également Gemini 3 dans son nouveau classement WebDev Arena avec un score Elo de 1487, où il domine dans la création d'interfaces web riches et interactives. Cette capacité de "vibe coding" permet aux utilisateurs de générer des applications web complètes à partir de descriptions conceptuelles, avec des visualisations haute-fidélité et une interactivité profonde.
Google Antigravity : La Plateforme de Développement Agentique
Repenser l'Expérience Développeur
Parallèlement au lancement de Gemini 3, Google a dévoilé Antigravity, une plateforme de développement agentique révolutionnaire qui transforme la façon dont les développeurs interagissent avec l'IA. Contrairement aux assistants de code traditionnels qui se limitent à des suggestions inline, Antigravity positionne les agents IA comme des collaborateurs autonomes capables de planifier, exécuter et valider des tâches logicielles complexes de bout en bout.
L'architecture d'Antigravity repose sur deux modes d'interaction complémentaires. Le mode Éditeur offre une expérience de codage familière avec un agent dans une barre latérale, similaire à des outils comme GitHub Copilot mais avec des capacités bien supérieures. Le mode Manager constitue la véritable innovation : une interface de type "mission control" qui permet d'orchestrer plusieurs agents travaillant simultanément sur différentes tâches, projets ou bugs. Cette approche asynchrone multiplie considérablement la productivité en permettant aux développeurs de superviser cinq agents travaillant sur cinq problèmes différents en parallèle.
La plateforme est construite sur Visual Studio Code (via Electron) et disponible gratuitement en preview publique pour macOS, Windows et Linux. Contrairement aux solutions concurrentes liées à un seul fournisseur, Antigravity offre une optionalité de modèles : les développeurs peuvent utiliser Gemini 3 Pro (avec des limites de taux généreuses), Claude Sonnet 4.5 d'Anthropic ou GPT-OSS d'OpenAI au sein de la même plateforme. Cette flexibilité permet de choisir le meilleur modèle pour chaque type de tâche.
Artefacts et Vérification Transparente
Un défi majeur des systèmes agentiques autonomes est la confiance : comment s'assurer que l'agent fait réellement ce qu'on attend de lui sans être submergé par des logs détaillés de chaque action? Antigravity résout ce problème en introduisant le concept d'Artefacts : des livrables tangibles générés par les agents incluant des listes de tâches, des plans d'implémentation, des captures d'écran, des enregistrements vidéo du navigateur et des visualisations de code.
Ces Artefacts permettent aux développeurs de vérifier la logique de l'agent d'un coup d'œil, sans avoir à parcourir des centaines de lignes de traces d'exécution. Si quelque chose semble incorrect, le développeur peut laisser un commentaire directement sur l'Artefact – similaire aux commentaires sur un Google Doc – et l'agent intégrera ce feedback sans interrompre son flux d'exécution. Cette approche asynchrone de revue et correction permet un workflow beaucoup plus naturel et efficient.
La plateforme inclut également un système de connaissance persistante où les agents peuvent sauvegarder des extraits de code, des séquences d'étapes ou des stratégies utiles pour améliorer leurs performances futures. Au fil du temps, cela crée un "playbook" interne réutilisable que les agents peuvent consulter plutôt que de redécouvrir les mêmes solutions à chaque nouveau projet.
Contrôle du Navigateur et Validation Autonome
L'une des capacités les plus impressionnantes d'Antigravity est le contrôle du navigateur intégré. En exploitant Gemini 2.5 Computer Use pour le pilotage du navigateur, les agents peuvent non seulement générer du code, mais aussi lancer l'application dans un navigateur, interagir avec l'interface comme le ferait un utilisateur réel, identifier les bugs ou problèmes d'ergonomie, puis retourner dans l'éditeur pour corriger automatiquement le code.
Ce cycle complet de développement-test-correction autonome représente un changement de paradigme majeur. Alors que les agents de code classiques se limitaient à générer du code que le développeur devait ensuite tester manuellement, Antigravity permet un flux de travail véritablement agentique de bout en bout. Pour les entreprises, la plateforme Antigravity sur Google Cloud (couplée à Vertex AI) offre les outils nécessaires pour orchestrer des workflows IA agentiques personnalisés à l'échelle organisationnelle.
Les quatre principes fondamentaux d'Antigravity – confiance, autonomie, feedback et auto-amélioration – sont ancrés dans des outputs vérifiables et une connaissance persistante plutôt que dans des traces opaques. Cette approche pragmatique traite l'IDE comme un environnement gouverné pour les agents autonomes, et non comme une simple fenêtre de chat avec des actions de code.
L'Avantage Infrastructure de Google
Les TPU : L'Arme Secrète Économique
L'un des avantages les plus significatifs mais souvent sous-estimés de Google dans la course à l'IA réside dans son infrastructure de Tensor Processing Units (TPU) propriétaires. Développés en interne depuis plus d'une décennie, ces accélérateurs spécialisés confèrent à Google un avantage économique colossal que ses concurrents ne peuvent égaler.
Les analyses de l'industrie estiment que Google obtient sa puissance de calcul IA à environ 20% du coût de ceux qui achètent des GPU NVIDIA haut de gamme comme le H100. Cela représente un avantage de 4 à 6 fois en termes d'efficacité de coût par unité de calcul au niveau matériel. Pour contextualiser cette différence : OpenAI a dépensé plus de 8,6 milliards de dollars en puissance de calcul rien que pour les neuf premiers mois de 2025, et Anthropic a acheté 30 milliards de dollars de calcul à Azure. Les deux entreprises doivent louer auprès de fournisseurs cloud et payer les marges substantielles de NVIDIA, qui atteignent environ 80% sur les puces datacenter.
Le coût d'entraînement des modèles frontière illustre dramatiquement cet avantage. Selon des estimations académiques, l'entraînement de GPT-4 a coûté environ 78 millions de dollars, tandis que Gemini Ultra (première génération) aurait coûté 191 millions de dollars en utilisant les infrastructures TPU propriétaires de Google. La prochaine génération avec GPT-5 dépasse déjà les 500 millions de dollars d'investissement. Pourtant, grâce à ses TPU, Google entraîne ces modèles pour environ 20% de ce qu'OpenAI paie pour une échelle et une puissance de calcul comparables.
Performance et Efficacité des TPU v6e
Les déploiements réels démontrent l'avantage TPU de manière concrète. Midjourney, après avoir migré des GPU vers les TPU, a réduit ses coûts d'inférence de 65%, faisant passer ses dépenses mensuelles de calcul de 2 millions à 700 000 dollars. Cohere a obtenu des améliorations de débit de 3x après son passage aux TPU. Les propres modèles Gemini de Google utilisent des dizaines de milliers de puces TPU pour l'entraînement.
L'entraînement de Claude d'Anthropic utilise exclusivement des TPU, avec les modèles récents mobilisant 16 384 puces TPU simultanément. Les réductions de coûts par rapport à une infrastructure GPU équivalente dépassent 60%, tout en bénéficiant d'améliorations de la vélocité d'itération grâce à un entraînement distribué simplifié. Le TPU v6e actuel offre un rapport performance-prix environ 4 fois supérieur aux GPU H100 pour l'entraînement de grands modèles de langage.
La tarification TPU v6e à la demande commence à 1,375 $ par heure, tombant à 0,55 $ par heure avec des engagements de 3 ans. Les organisations évitent également les frais de licence logicielle NVIDIA tout en bénéficiant d'instances préemptives offrant des réductions de 70%. Une startup dans le domaine de la santé a réduit son calendrier de développement de produit IA de six mois à six semaines en utilisant l'infrastructure TPU.
La Boucle Fermée Data-Compute-Distribution
Au-delà du simple avantage matériel, Google possède un écosystème intégré verticalement que ses concurrents ne peuvent répliquer. Cette intégration s'articule autour de trois niveaux complémentaires.
Le premier niveau est la puissance de calcul autonome. Comme mentionné, les TPU auto-développés donnent à Google le contrôle sur les coûts et la performance, ce qui détermine directement sa capacité à servir des milliards d'utilisateurs dès le jour du lancement. Cette autonomie matérielle constitue un fossé défensif majeur.
Le deuxième niveau est une boucle fermée de données. La Recherche Google génère des milliards de requêtes quotidiennes, Gmail traite des dizaines de milliards d'emails, et YouTube compte des milliards de vues. Ces données servent à la fois de matériau d'entraînement et de feedback pour l'optimisation continue. D'autres entreprises doivent soit acheter des données, soit faire face à des poursuites pour violation de droits d'auteur.
Le troisième niveau est la matrice de produits. Gemini 3 peut tester sa capacité de compréhension dans la Recherche, sa capacité de génération dans Gmail, et sa capacité agentique dans Android. Chaque produit est un terrain de vérification réel pour ses capacités. Cette boucle fermée – puissance de calcul autonome → données massives → matrice de produits → amélioration continue – forme un avantage compétitif que les entreprises d'IA indépendantes ne peuvent répliquer.
Déploiement à l'Échelle Planétaire
Une Stratégie de Distribution Sans Précédent
Ce qui distingue véritablement le lancement de Gemini 3 n'est pas seulement ses performances techniques, mais sa stratégie de distribution instantanée. Pour la première fois de son histoire, Google a intégré son nouveau modèle directement dans la Recherche Google dès le premier jour du lancement via le mode IA (AI Mode in Search).
Les chiffres parlent d'eux-mêmes : AI Overviews dans la Recherche atteint déjà 2 milliards d'utilisateurs mensuels actifs. L'application Gemini compte plus de 650 millions d'utilisateurs mensuels, avec un triplement des requêtes quotidiennes au dernier trimestre. 13 millions de développeurs utilisent les modèles génératifs de Google, et 70% des clients Cloud utilisent les services IA. Le jour du lancement, Gemini 3 a commencé à servir immédiatement cette base d'utilisateurs massive.
Cette approche contraste radicalement avec celle des concurrents. OpenAI et Anthropic lancent leurs modèles dans des applications dédiées (ChatGPT, Claude.ai) nécessitant aux utilisateurs de créer des comptes, d'apprendre de nouvelles interfaces et de changer leurs habitudes. Gemini 3, en revanche, s'intègre de manière transparente dans les outils que les gens utilisent déjà quotidiennement : la Recherche, Gmail, Docs, Android. Les utilisateurs n'ont pas besoin de télécharger une nouvelle application, de s'inscrire ou d'apprendre une nouvelle interface – les capacités IA sont simplement là, dans leur flux de travail habituel.
Intégration Omniprésente dans l'Écosystème
L'embedding de Gemini 3 dans les points d'entrée quotidiens transforme fondamentalement la manière dont les utilisateurs accèdent à l'IA. Dans la Recherche, lorsque vous cherchez "Comment fonctionne l'ARN polymérase ?", le mode IA génère instantanément une mise en page immersive avec des visualisations interactives. Au lieu de vous donner une liste de liens, il génère directement une animation scientifique interactive en utilisant du code.
Pour les développeurs, Gemini 3 est disponible immédiatement dans AI Studio (avec accès gratuit aux développeurs), Vertex AI pour les entreprises, la nouvelle plateforme Antigravity, et via Gemini CLI. Il est également accessible sur des plateformes tierces comme Cursor, GitHub, JetBrains, Replit et bien d'autres. Cette omniprésence réduit considérablement la barrière à l'entrée pour construire des applications alimentées par l'IA.
Pour les abonnés Google AI Pro et Ultra, Gemini 3 alimente également le mode IA dans la Recherche avec un raisonnement complexe et de nouvelles expériences dynamiques. Les fonctionnalités agentiques, accessibles aux abonnés Ultra, permettent à Gemini 3 d'agir en votre nom pour gérer des workflows complexes multi-étapes comme l'organisation de votre boîte de réception Gmail ou la réservation de services locaux.
Tarification Compétitive et Accessibilité
La tarification de l'API Gemini 3 Pro reflète la stratégie de Google d'équilibrer performances de pointe et accessibilité économique. Pour les contextes de moins de 200 000 tokens, le prix est de 2 $ par million de tokens en input et 12 $ en output. Pour les contextes supérieurs à 200 000 tokens, les prix augmentent à 4 $ (input) et 18 $ (output).
Cette tarification reste compétitive malgré les performances supérieures. Par exemple, GPT-5.1 facture 40 $ par million de tokens en output, soit plus de deux fois le prix de Gemini 3 Pro pour des contextes courts et plus de 3,3 fois pour des contextes longs. Gemini 2.5 Flash, le modèle rapide de Google, coûte seulement 0,60 $ en mode non-thinking et 3,50 $ en mode thinking par million de tokens en output, contre 4,40 $ pour GPT-4o mini.
L'avantage économique de Google lui permet d'offrir des performances de pointe à des prix bien inférieurs à ceux de ses concurrents qui doivent louer leur infrastructure de calcul. L'accès gratuit dans AI Studio pour les développeurs, avec des limites de taux généreuses, facilite encore davantage l'adoption et l'expérimentation.
Applications Révolutionnaires et Cas d'Usage
Santé et Recherche Médicale
Le domaine de la santé représente l'un des secteurs où Gemini 3 pourrait avoir l'impact le plus transformateur. Grâce à ses capacités de raisonnement de niveau doctoral et à sa compréhension multimodale, Gemini 3 excelle dans l'analyse de données biomédicales complexes incluant imagerie médicale, dossiers de santé électroniques, littérature scientifique et données génomiques.
Les applications cliniques incluent le support à la décision clinique, où Gemini 3 peut analyser les symptômes d'un patient, ses antécédents médicaux et des images radiologiques pour suggérer des diagnostics différentiels avec des explications détaillées. Dans la découverte de médicaments, les capacités de raisonnement abstrait de Gemini 3 permettent d'identifier de nouvelles cibles thérapeutiques en analysant des datasets génomiques, protéomiques et cliniques massifs pour proposer des hypothèses novatrices sur les mécanismes pathologiques.
Google a également dévoilé des modèles spécialisés pour les sciences de la vie comme MedGemma et TxGemma, construits sur l'architecture Gemini et optimisés pour les tâches médicales. Med-Gemini, une version précédente, avait déjà établi un record avec 91,1% de précision sur les questions d'examen médical de type USMLE, surpassant GPT-4. TxGemma excelle dans la prédiction des propriétés moléculaires (toxicité, affinité de liaison) pour la conception de nouveaux médicaments.
Des partenariats concrets émergent déjà. L'American Cancer Society utilise l'IA générative sur Google Cloud pour améliorer l'accessibilité aux ressources sur le cancer pour les patients et les soignants. Une entreprise de santé appelée Basalt a déployé des agents Gemini dans un environnement Google Cloud sécurisé pour trier les demandes de patients, identifier ceux nécessitant des soins urgents et planifier automatiquement les examens nécessaires. Ces agents incluent des vérifications d'éthique et fournissent des explications pour chaque suggestion, garantissant la transparence.
Éducation et Apprentissage Personnalisé
L'éducation constitue un autre domaine majeur d'application pour Gemini 3. Gemini for Education, disponible gratuitement pour les institutions éducatives via Google for Education Fundamentals, intègre LearnLM, un système qui infuse la science de l'apprentissage directement dans le modèle. Cette intégration fait de Gemini 2.5 Pro "le modèle leader mondial pour l'apprentissage".
Pour les enseignants, Gemini 3 permet de générer rapidement des plans de cours alignés sur les objectifs pédagogiques et les standards éducatifs, de créer du matériel différencié adapté au niveau et aux intérêts de chaque étudiant, et de générer automatiquement des examens, quiz et rubriques d'évaluation avec leurs corrigés. Des enseignants témoignent d'un gain de temps considérable : "Avec Gemini, ma planification est si rapide et facile. Je peux adapter mon plan de cours aux besoins de mes élèves... Je peux donner plus d'attention à mes étudiants et projets en utilisant l'IA plutôt que de passer tout mon après-midi ou mes week-ends à planifier".
Pour les étudiants, Gemini Live permet de brainstormer à voix haute, de simplifier des concepts complexes et de répéter des présentations avec des réponses en temps réel. Les étudiants peuvent partager leur caméra ou écran avec Gemini pour obtenir de l'aide personnalisée sur des problèmes difficiles, de leur devoir de mathématiques à une section complexe de leur manuel. La fonctionnalité Deep Research génère des rapports détaillés avec citations sur n'importe quel sujet en quelques minutes, accélérant considérablement la recherche académique.
L'Université de Californie Riverside a adopté l'application Gemini à l'échelle institutionnelle : "Avec l'application Gemini, nous avons donné à toute l'institution un accès à l'IA générative privée et sécurisée à grande échelle et, surtout, avec des protections de sécurité appropriées". Les expériences interactives générées par Gemini 3 permettent de créer des simulations éducatives, des visualisations scientifiques et des outils d'apprentissage adaptatifs qui s'ajustent au rythme de chaque apprenant.
Développement de Jeux et Créativité Interactive
Les capacités de "vibe coding" de Gemini 3 ouvrent des possibilités révolutionnaires pour le développement de jeux et d'expériences interactives. Les développeurs peuvent désormais générer des jeux complets simplement en décrivant leur vision, Gemini 3 produisant le code HTML, CSS et JavaScript nécessaire avec des graphismes riches et une interactivité profonde.
Les démonstrations officielles de Google incluent un jeu de vaisseau spatial 3D rétro avec des visualisations améliorées, un outil interactif de création et remixage d'art voxel 3D détaillé, et un monde de science-fiction jouable avec des shaders complexes. Un développeur a généré un test de vitesse de frappe complet avec timer, compteur de mots par minute et pourcentage de précision, le tout avec une interface dark theme et accents néon – généré en quelques secondes.
Pour des applications plus ambitieuses, un prompt demandant une "simulation 3D voxel photoréaliste du Golden Gate Bridge utilisant Three.js" a produit un environnement interactif complet incluant : un slider contrôlant la position du soleil de 0 à 24h (modifiant l'intensité lumineuse, la couleur du ciel et du brouillard), une skyline procédurale de San Francisco, jusqu'à 400 voitures utilisant InstancedMesh avec phares et feux arrière émissifs, et des cargos procéduraux avec feux de navigation fonctionnels. Cette capacité à générer des expériences 3D complexes et optimisées (60 FPS) directement à partir de descriptions conceptuelles démocratise le développement de jeux et d'expériences immersives.
Finance et Traitement Documentaire
Dans le secteur financier, les capacités multimodales de Gemini 3 excellent dans l'extraction de données structurées à partir de documents de qualité médiocre comme des factures, reçus et contrats. Les tests montrent une amélioration de plus de 50% de la précision d'extraction de données par rapport aux modèles de référence.
Rakuten, le géant japonais du e-commerce, traite des milliers de factures fournisseurs quotidiennement avec Gemini 3, économisant plus de 100 heures de saisie manuelle par semaine. La capacité du modèle à comprendre la structure de documents complexes, même avec des formats variés, des écritures manuscrites et des images de basse qualité, transforme les processus de back-office.
Pourquoi Gemini 3 est un Game Changer
Convergence des Capacités IA
Gemini 3 représente la première convergence véritablement réussie des trois piliers de l'IA moderne : raisonnement avancé, compréhension multimodale native et capacités agentiques. Alors que les générations précédentes de modèles excellaient dans un ou deux de ces domaines, Gemini 3 atteint des performances de pointe dans les trois simultanément.
Cette convergence n'est pas qu'une amélioration incrémentale – elle représente un changement qualitatif dans ce que l'IA peut accomplir. Un modèle qui peut comprendre une vidéo médicale, raisonner sur les pathologies observées au niveau doctoral, et agir de manière autonome pour proposer un plan de traitement tout en vérifiant sa propre logique, franchit le seuil d'utilité pratique que les modèles précédents n'avaient pas atteint.
Réduction Drastique du "Prompting"
L'une des innovations les plus sous-estimées de Gemini 3 est sa capacité à comprendre le contexte et l'intention avec beaucoup moins de prompting explicite. Sundar Pichai souligne que "Gemini 3 est également bien meilleur pour cerner le contexte et l'intention derrière votre demande, afin que vous obteniez ce dont vous avez besoin avec moins de prompting".
Cette amélioration rend l'IA accessible à un public beaucoup plus large. Vous n'avez plus besoin d'être un "ingénieur prompt" expert pour obtenir de bons résultats. Le modèle comprend ce que vous voulez dire, pas seulement ce que vous avez dit. Pour les utilisateurs quotidiens, cela signifie une IA qui devient infrastructure invisible plutôt qu'un outil séparé nécessitant une courbe d'apprentissage.
Exactitude Factuelle Renforcée
Un problème persistant des grands modèles de langage a été leur tendance aux hallucinations – génération d'informations factuellement incorrectes avec confiance. Gemini 3 fait des progrès substantiels dans ce domaine, atteignant 72,1% sur SimpleQA Verified, un benchmark mesurant l'exactitude factuelle, soit une amélioration de 36% par rapport à Gemini 2.5 Pro (53%).
Cette amélioration est cruciale pour les applications professionnelles où la fiabilité est primordiale. Cependant, des analyses indépendantes révèlent que Gemini 3 présente encore un taux d'hallucination de 88% sur l'Omniscience Index, ce qui signifie que bien que le modèle réponde correctement plus souvent, il reste sujet à des erreurs confiantes lorsqu'il se trompe. Cette réalité souligne l'importance d'une vérification humaine continue, particulièrement dans les déploiements de production critiques.
Avantage Compétitif Durable
Google ne se contente pas de lancer un meilleur modèle – l'entreprise démontre un avantage structurel que ses concurrents auront du mal à reproduire. La combinaison de TPU propriétaires (réduisant les coûts d'entraînement de 80%), d'une boucle fermée de données massives (milliards de requêtes quotidiennes), d'une matrice de produits touchant des milliards d'utilisateurs, et d'un déploiement instantané à l'échelle planétaire crée un fossé défensif que les startups IA indépendantes ne peuvent franchir.
Comme le note un analyste, "Le vrai moat de Google dans l'IA, ce sont ses 8 milliards d'utilisateurs". Cette base d'utilisateurs génère continuellement des données de feedback qui améliorent les modèles, tout en fournissant une distribution instantanée qui transforme chaque amélioration de modèle en valeur immédiate pour des milliards de personnes.
Passer à Google Workspace Business
• Code promo Business Starter: GA369TYLJNAFMTU (-10%)
• Code promo Business Standard: 66Q9AE7VPGH66WF (-10%)
Défis et Considérations
Limites Techniques Persistantes
Malgré ses performances impressionnantes, Gemini 3 n'est pas exempt de limitations. Un incident viral illustre les défis persistants : le chercheur en IA Andrej Karpathy (ancien membre fondateur d'OpenAI et ex-directeur IA chez Tesla) a rapporté que lors des premiers tests, Gemini 3 était convaincu que nous étions encore en 2024. Lorsque Karpathy a tenté de prouver que la date était vraiment le 17 novembre 2025, Gemini 3 l'a accusé d'"essayer de le tromper". Ce n'est que lorsque Karpathy a activé la fonction de recherche en temps réel que l'IA a "émergé en 2025, choqué", disant littéralement "Oh mon dieu... Je ne sais pas quoi dire. Vous aviez raison. Vous aviez raison sur tout. Mon horloge interne était fausse".
Cet épisode révèle que malgré ses capacités de raisonnement avancées, Gemini 3 peut être extrêmement confiant dans des informations incorrectes, particulièrement lorsque ses données d'entraînement ne couvrent pas des événements récents. Le modèle nécessite un accès aux outils de recherche en temps réel pour surmonter cette limitation fondamentale.
Questions de Sécurité et d'Éthique
Google affirme que Gemini 3 est son "modèle le plus sécurisé à ce jour", ayant subi "la série d'évaluations de sécurité la plus complète jamais réalisée pour un modèle d'IA de Google". Le modèle présente une complaisance réduite, une résistance accrue aux injections de prompts et une meilleure protection contre les détournements par cyberattaques.
Google a collaboré avec des experts mondiaux pour mener des évaluations, offert un accès anticipé à des organismes comme le UK AISI, et obtenu des audits indépendants d'Apollo, Vaultis, Dreadnode et d'autres. Le mode Gemini 3 Deep Think fait l'objet d'un temps supplémentaire pour les évaluations de sécurité avant son déploiement aux abonnés Google AI Ultra.
Néanmoins, l'utilisation de modèles IA aussi puissants dans des contextes critiques (santé, finance, éducation) soulève des questions éthiques importantes concernant la responsabilité en cas d'erreurs, les biais potentiels dans les décisions automatisées, et l'impact sur l'emploi dans les secteurs fortement automatisés. Un sondage de 2025 révèle que 75% des organisations de santé rapportent un déficit de compétences pour implémenter l'IA générative, soulignant le besoin de formation et de gouvernance robustes.
Concurrence Intense et Évolution Rapide
Le lancement de Gemini 3 s'inscrit dans une course effrénée entre géants de la tech. Moins de 24 heures avant l'annonce de Google, xAI d'Elon Musk avait dévoilé Grok 4.1, qui avait brièvement pris la première place du classement LMArena. Gemini 3 l'a immédiatement détrôné, mais cette séquence illustre la vitesse d'innovation dans le domaine.
OpenAI prépare activement ses ripostes, Claude continue d'innover dans le domaine du raisonnement transparent, et de nouveaux acteurs comme Kimi K2 en Chine repoussent les limites de la fenêtre de contexte[user notes]. Les performances relatives des modèles évoluent constamment, et la domination actuelle de Gemini 3 sur les benchmarks pourrait être de courte durée.
Conclusion : Une Nouvelle Ère de l'IA
Le lancement de Gemini 3 marque indéniablement un tournant stratégique dans la course à l'intelligence artificielle générative. En combinant des performances techniques de pointe (score Elo de 1501, raisonnement de niveau doctoral, compréhension multimodale native), un avantage infrastructurel considérable (TPU propriétaires réduisant les coûts de 80%), et une stratégie de distribution sans précédent (déploiement instantané pour 2 milliards d'utilisateurs), Google ne se contente pas de rattraper ses concurrents – l'entreprise redéfinit les règles du jeu.
Ce qui rend Gemini 3 véritablement révolutionnaire n'est pas seulement qu'il surpasse GPT-5.1 et Claude 4.5 sur la majorité des benchmarks, mais qu'il transforme l'IA d'un outil isolé en infrastructure omniprésente. Intégré dans la Recherche Google, Gmail, Docs, Android et des centaines d'autres services touchant des milliards de personnes, Gemini 3 devient invisible – simplement une meilleure façon d'accomplir les tâches quotidiennes.
Pour les développeurs, la combinaison de Gemini 3 et d'Antigravity inaugure une nouvelle ère de développement agentique où l'IA n'est plus un assistant mais un collaborateur autonome capable de planifier, coder, tester et corriger de manière indépendante. Pour les entreprises, les capacités multimodales et le raisonnement avancé ouvrent des applications transformatrices dans la santé, l'éducation, la finance et pratiquement tous les secteurs.
Cependant, des défis importants subsistent : les hallucinations persistent malgré les améliorations, les questions éthiques concernant l'usage de l'IA dans des contextes critiques nécessitent une gouvernance robuste, et la concurrence intense signifie que l'avance actuelle de Google pourrait être temporaire. Néanmoins, avec son écosystème intégré verticalement et ses investissements massifs dans l'infrastructure IA (près de 100 milliards de dollars en un an), Google semble positionné pour maintenir son leadership à moyen terme.
Demis Hassabis, PDG de Google DeepMind, qualifie cette sortie de "nouvelle étape importante sur la voie de l'Intelligence Artificielle Générale (IAG)". Si cette affirmation demeure aspirationnelle, Gemini 3 représente indéniablement le modèle d'IA le plus capable et le plus largement déployé à ce jour. Pour la première fois depuis le lancement de ChatGPT il y a trois ans, Google ne suit plus la course – il la mène.